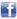Las máquinas están aprendiendo a ganar dinero en Bolsa
por Carlos Montero •Hace 6 años
•Hace 6 años

 0.00
0.00El banco francés Societe Generale ha emitido una nota de análisis comparando los resultados de las operaciones de las computadoras - algoritmos de aprendizaje automático - frente a estrategias más básicas de selección de valores. Spoiler: en su mayoría ganan, pero en los últimos dos años han ganado los humanos.
Las diversas barras de colores reflejan el rendimiento de diferentes enfoques del aprendizaje automático utilizando un conjunto de datos de 80 factores fundamentales y técnicos sobre un promedio de 1.000 acciones cotizadas desde diciembre de 1989 hasta septiembre de 2017.
Las acciones están tomadas del índice FTSE Developed World, pero excluyen a las compañías financieras. El modelo de referencia negro "Todos los factores" simplemente utiliza un promedio ponderado de los factores.
El claro ganador es el algoritmo de máquina de vector de soporte no lineal (SVM). Agárrese a la silla un momento mientras trato de explicar qué es eso.
En este caso, la pregunta que debe responderse es si se debe adoptar una posición larga (comprados) o corta (vendidos) dada la información disponible (los factores). Por lo tanto, los algoritmos de aprendizaje automático van a analizar los datos y predecir si se pondrán largos o cortos. Esa decisión será correcta o incorrecta, y el algoritmo usará esa retroalimentación para ajustarse.
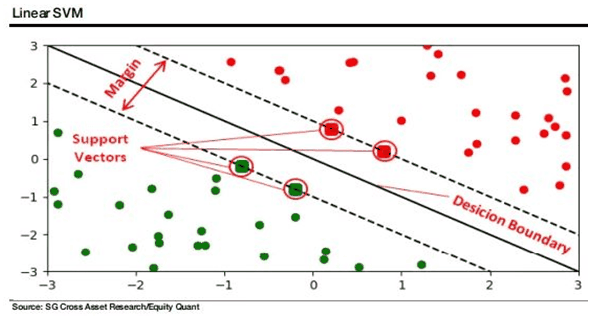
Un algoritmo SVM básicamente trata de identificar patrones en un conjunto de datos, y por lo tanto, divide los datos en dos grupos dibujando una línea entre ellos. Todo es esto o aquello. Una decisión binaria. Largo o corto. La idea es encontrar una línea que tenga el mayor margen entre los dos grupos, creando así una distinción lo más clara posible.
Este tipo de algoritmo destaca muy bien por qué es difícil explicar qué está sucediendo 'dentro' de un algoritmo de aprendizaje automático. Si hay una línea lineal clara que divide el conjunto de datos, entonces explicar los patrones que separan esto y aquello es algo sencillo, y no muy difícil de visualizar:
Pero si el patrón en los datos no es lineal, entonces un truco es agregar matemáticamente dimensiones adicionales a los datos hasta que se pueda crear una separación lineal clara:
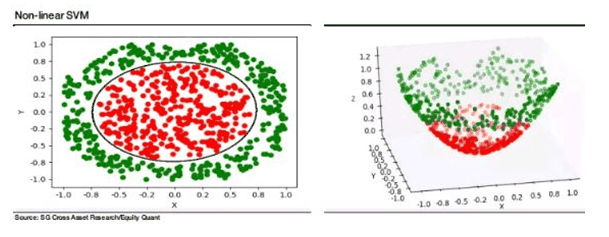
La situación puede ser más complicada que la imagen anterior, con más y más dimensiones necesarias antes de que se pueda encontrar un ajuste lineal. Como resultado, "no es posible visualizar muchos de los pasos involucrados en el cálculo, y por lo tanto la interpretación de los resultados puede ser muy desafiante", escriben Georgios Oikonomou y Andrew Lapthorne en la nota. "Esto es obviamente una desventaja clave cuando se usa para diseñar estrategias de inversión".
De todos modos, los algoritmos de aprendizaje automático funcionan bastante bien en general y luego fallan en 2016 y 2017:
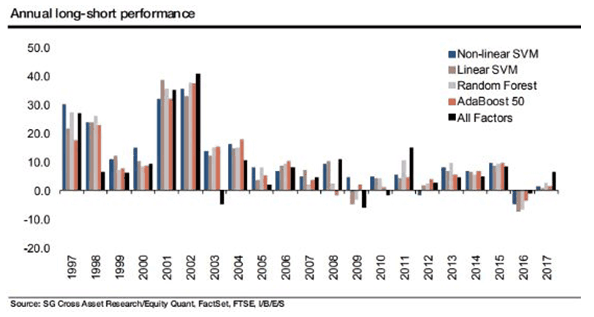
Oikonomou nos dijo que el rendimiento diferente de los diversos algoritmos se debe principalmente a los datos. Por ejemplo, la SVM no lineal podría funcionar mejor que la SVM lineal porque "para ciertos factores podría ser que las puntuaciones altas sean buenas para el rendimiento de las acciones, pero las puntuaciones bajas no son malas. Este es un patrón no lineal que un modelo lineal no puede acomodar del algoritmo SVM no lineal".
Pero que todos los algoritmos no hayan tenido un buen rendimiento en 2016 y 2017 pone de relieve el viejo problema de los modelos.
"2016 fue un año complicado", dice Oikonomou, y señala que los algoritmos "no manejaron cambios bruscos en el mercado".
"Incluso este año se podría argumentar que el mercado no está impulsado por los fundamentales", agrega, que tal vez no sea el mejor entorno para un modelo capacitado para detectar patrones históricos en los fundamentales.
En otras palabras, el rendimiento pasado no es indicativo de rendimientos futuros.